This is the last post of the year.
I'd like that the readers criticize, comment, discuss, make corrections and observations in next posts.
I learn a lot of things in this year and I'd want to share this knowledge to the readers.
The last desire is peace, success and blessings of God to everybory.
quarta-feira, 31 de dezembro de 2008
Por fim....
Este será o último post do ano.
Espero que no próximo ano, os leitores critiquem, comentem, discutam, façam correções e observações aqui no MultiSign.
Acho que aprendi muito este ano e espero ter passado algo para os leitores.
A enquete sobre o que você procura ou gosta de ver aqui no blog está no final, mas ainda faltam algumas horas até ser fechada então quem quiser ainda pode votar.
Para fechar o ano, desejo paz, sucesso e bênçãos sobre todos.
Espero que no próximo ano, os leitores critiquem, comentem, discutam, façam correções e observações aqui no MultiSign.
Acho que aprendi muito este ano e espero ter passado algo para os leitores.
A enquete sobre o que você procura ou gosta de ver aqui no blog está no final, mas ainda faltam algumas horas até ser fechada então quem quiser ainda pode votar.
Para fechar o ano, desejo paz, sucesso e bênçãos sobre todos.
terça-feira, 23 de dezembro de 2008
Linux Foundation faz concurso para para marketing/publicidade
Olhem esta fonte.
Agora que já estão todos informados, cabe às mentes brilhantes e voadoras do software livre a tarefa de desenvolver o nosso comercial.
Pensemos um pouco: a Micro$oft faz propagandas em sites, revistas, outdoors, vídeos, etc... a Ma€, idem e ainda faz ofensivas a Micro$oft.
E quanto ao GNU/Linux? Nada de propagandas em mídia, apenas sites que falam a respeito e as empresas que desenvolvem soluções em software livre que divulgam o nosso querido sistema operacional.
Por que será então que o nosso sitema é o que ganha mais adeptos? O que tem mais atualizações a cada ano? O que é mais usado em servidores e sistemas de grande porte?
Parece que o marketing não é um ponto chave para os especialistas da área, mas a ignorância da grande massa sobre os benefícios do GNU/Linux é provavelmente a maior barreira para a adoção do nosso pinguim em casas, firmas, escritórios, etc...
Então, fica a sugestão para os marqueteiros que vão se aventurar a fazer os vídeos para divulgar nosso sistema operacional: explorem os benefícios do software livre sobre o proprietário, com o melhor bom humor possível.
Segue uma idéia que tive:
Uma pessoa usando seu PC e este trava (o que o ruindow$ faz de melhor). Então a pessoa liga para a assistência técnica e este faz uma lista de "sugestões" tipo aumentar memória RAM, formatar o PC (esta é a prioridade), comprar anti-vírus, instalar uma versão mais recente do sistema, etc...
Depois, desanimada, a pessoa começa a ver TV (por exemplo) e assiste ao próprio comercial, mas em vez de ligar para uma assistência técnica tradicional ela chama um profissional de software livre que vai apresentar todas as vantagens do software livre como o custo, o hardware necessário, todos os recursos disponíveis (procurar explorar o Compiz), etc...
Por fim a pessoa faz a mudança para o software livre e vive feliz para sempre.
Agora que já estão todos informados, cabe às mentes brilhantes e voadoras do software livre a tarefa de desenvolver o nosso comercial.
Pensemos um pouco: a Micro$oft faz propagandas em sites, revistas, outdoors, vídeos, etc... a Ma€, idem e ainda faz ofensivas a Micro$oft.
E quanto ao GNU/Linux? Nada de propagandas em mídia, apenas sites que falam a respeito e as empresas que desenvolvem soluções em software livre que divulgam o nosso querido sistema operacional.
Por que será então que o nosso sitema é o que ganha mais adeptos? O que tem mais atualizações a cada ano? O que é mais usado em servidores e sistemas de grande porte?
Parece que o marketing não é um ponto chave para os especialistas da área, mas a ignorância da grande massa sobre os benefícios do GNU/Linux é provavelmente a maior barreira para a adoção do nosso pinguim em casas, firmas, escritórios, etc...
Então, fica a sugestão para os marqueteiros que vão se aventurar a fazer os vídeos para divulgar nosso sistema operacional: explorem os benefícios do software livre sobre o proprietário, com o melhor bom humor possível.
Segue uma idéia que tive:
Uma pessoa usando seu PC e este trava (o que o ruindow$ faz de melhor). Então a pessoa liga para a assistência técnica e este faz uma lista de "sugestões" tipo aumentar memória RAM, formatar o PC (esta é a prioridade), comprar anti-vírus, instalar uma versão mais recente do sistema, etc...
Depois, desanimada, a pessoa começa a ver TV (por exemplo) e assiste ao próprio comercial, mas em vez de ligar para uma assistência técnica tradicional ela chama um profissional de software livre que vai apresentar todas as vantagens do software livre como o custo, o hardware necessário, todos os recursos disponíveis (procurar explorar o Compiz), etc...
Por fim a pessoa faz a mudança para o software livre e vive feliz para sempre.
sábado, 20 de dezembro de 2008
Lighting manipulation by histogram
I did a post about segmentation (in portuguese), in that post I cited a histogram's equalization, and, I'm working with enhancement for my DIP class, so I will show a very simple technique here.
I use just Scilab and SIVP for develop my codes (search for scilab and sivp tags here in the blog).
Ok, let's do a offset manipulation in the image's histogram. This technique consists in add or subtract a constant value in all pixels.
See the picture.

Its histogram is this.

Ps.: The histogram is the number of pixels for each value (send comments for any question).
This is a lighter image, and its histogram is concentrate in higher values. Thus, let's subtract a constant value 50 of each pixel.
The result.
 Old imagem | New image.
Old imagem | New image.
And the hew histogram.

The technique is very simple, but the simplest form is the best in many cases.
If anyone wants more about histogram's manipulation then send me comments.
I use just Scilab and SIVP for develop my codes (search for scilab and sivp tags here in the blog).
Ok, let's do a offset manipulation in the image's histogram. This technique consists in add or subtract a constant value in all pixels.
See the picture.

Its histogram is this.

Ps.: The histogram is the number of pixels for each value (send comments for any question).
This is a lighter image, and its histogram is concentrate in higher values. Thus, let's subtract a constant value 50 of each pixel.
The result.
 Old imagem | New image.
Old imagem | New image.And the hew histogram.

The technique is very simple, but the simplest form is the best in many cases.
If anyone wants more about histogram's manipulation then send me comments.
quinta-feira, 18 de dezembro de 2008
Pela vida
Hoje é comum vermos casos de aborto pelo mundo afora.
Aqui no Brasil, abortos são considerados abomináveis, principalmente porque temos uma forte tradição cristã.
Na América do Norte e Europa, a prática do aborto é comum, e porque eles são "os donos do mundo" querem disceminar a cultura abortista.
Sei que este blog trata principalmente de tecnologia, mas eu acredito que toda tecnologia deve ser desenvolvida a favor da vida e que toda vida é preciosa, principalmente vidas inocentes.
Vamos ler este texto primeiro. Agora vamos refletir sobre um ponto: o que é o aborto?
Aborto é a retirada de um feto do útero materno antes que este esteja pronto para nascer.
Este vídeo mostra a técnica mais usada para realização de um aborto.
Pensemos, em que momento começa a vida de um ser humano?
No momento do nascimento, talvez?
Não! Ainda no útero da mãe, o feto já responde a estímulos e tem movimentos próprios.
Em algum momento durante a gestação? Não! Desde que o espermatozóide se une ao óvulo eles começam a se desenvolver como um novo ser que está sendo constituído.
Então podemos concluir que a criação do novo ser humano ocorre no momento da união entre o espermatozóide e o óvulo.
Se este ser humano, ainda feto, já é vivo e retirá-lo do útero da mãe implica em matá-lo, então uma mãe que pratica o aborto mata seu próprio filho.
Nos mandamentos da lei de Deus está escrito: "Não matarás.", imagine então matar o próprio filho e pior ainda, dentro do seu próprio corpo.
Um povo que se diz cristão, como os norte-americanos e europeus, deveria conhecer o que diz a palavra de Deus para assim buscar fazer o que é certo.
Aqui no Brasil, abortos são considerados abomináveis, principalmente porque temos uma forte tradição cristã.
Na América do Norte e Europa, a prática do aborto é comum, e porque eles são "os donos do mundo" querem disceminar a cultura abortista.
Sei que este blog trata principalmente de tecnologia, mas eu acredito que toda tecnologia deve ser desenvolvida a favor da vida e que toda vida é preciosa, principalmente vidas inocentes.
Vamos ler este texto primeiro. Agora vamos refletir sobre um ponto: o que é o aborto?
Aborto é a retirada de um feto do útero materno antes que este esteja pronto para nascer.
Este vídeo mostra a técnica mais usada para realização de um aborto.
Pensemos, em que momento começa a vida de um ser humano?
No momento do nascimento, talvez?
Não! Ainda no útero da mãe, o feto já responde a estímulos e tem movimentos próprios.
Em algum momento durante a gestação? Não! Desde que o espermatozóide se une ao óvulo eles começam a se desenvolver como um novo ser que está sendo constituído.
Então podemos concluir que a criação do novo ser humano ocorre no momento da união entre o espermatozóide e o óvulo.
Se este ser humano, ainda feto, já é vivo e retirá-lo do útero da mãe implica em matá-lo, então uma mãe que pratica o aborto mata seu próprio filho.
Nos mandamentos da lei de Deus está escrito: "Não matarás.", imagine então matar o próprio filho e pior ainda, dentro do seu próprio corpo.
Um povo que se diz cristão, como os norte-americanos e europeus, deveria conhecer o que diz a palavra de Deus para assim buscar fazer o que é certo.
segunda-feira, 15 de dezembro de 2008
Google Maps agora também com transporte público
As pessoas de algumas cidades do mundo já podem contar com o Google Maps para encontrar rotas de transporte público para seus destinos (fonte).
Atualmente, muitas cidades têm serviço de encontrar destinos a pé e de carro, porém é de conhecimento comum que não é possível para todo mundo ir a pé ou de carro para qualquer lugar, então surge um problema: como ir de transporte público (ônibus, metrô, trem, topic, etc....)?
Pois bem, espero que logo este recurso esteja disponível aqui em Fortaleza e em todas as cidades que são servidas de transporte público.
Atualmente, muitas cidades têm serviço de encontrar destinos a pé e de carro, porém é de conhecimento comum que não é possível para todo mundo ir a pé ou de carro para qualquer lugar, então surge um problema: como ir de transporte público (ônibus, metrô, trem, topic, etc....)?
Pois bem, espero que logo este recurso esteja disponível aqui em Fortaleza e em todas as cidades que são servidas de transporte público.
domingo, 14 de dezembro de 2008
Manipulação de iluminação pelo histograma
Eu fiz um post sobre segmentação em que eu citei uma equalização de histograma, mas como atualmente estou fazendo alguns testes com realce de imagens e usando técnicas que envolvem o histograma das imagens, vou apresentar algo aqui.
Para começar, tudo o que for apresentado aqui foi desenvolvido no Scilab com a biblioteca SIVP (informações podem ser encontradas facilmente nas tags do blog).
Pois bem, para começar vamos manipular apenas um offset do histograma que consiste em acrescentar ou subtrair um valor constante em todos os pixels da imagem.
Para ilustrar, vamos usar a imagem a seguir.

Segue o histograma desta imagem.
 Obs.: Lembrando que o histograma é a incidência de pixels em cada nível (intensidade).
Obs.: Lembrando que o histograma é a incidência de pixels em cada nível (intensidade).
Observando este histograma, percebe-se que ele está muito consentrado nos valores altos, o que se reflete em uma imagem muito clara.
Vamos então reduzir 50 de cada pixel.
Obtemos a imagem (original | nova).

E o novo histograma.

Neste caso, já percebe-se alguma diferença na imagem.
Para fechar o post, faço 2 observações:
Para começar, tudo o que for apresentado aqui foi desenvolvido no Scilab com a biblioteca SIVP (informações podem ser encontradas facilmente nas tags do blog).
Pois bem, para começar vamos manipular apenas um offset do histograma que consiste em acrescentar ou subtrair um valor constante em todos os pixels da imagem.
Para ilustrar, vamos usar a imagem a seguir.

Segue o histograma desta imagem.
 Obs.: Lembrando que o histograma é a incidência de pixels em cada nível (intensidade).
Obs.: Lembrando que o histograma é a incidência de pixels em cada nível (intensidade).Observando este histograma, percebe-se que ele está muito consentrado nos valores altos, o que se reflete em uma imagem muito clara.
Vamos então reduzir 50 de cada pixel.
Obtemos a imagem (original | nova).

E o novo histograma.

Neste caso, já percebe-se alguma diferença na imagem.
Para fechar o post, faço 2 observações:
- As imagens podem ser vistas em tamanho original apenas clicando em cima.
- Novos posts sobre o assunto serão feitos caso os leitores mostrem interesse.
quarta-feira, 10 de dezembro de 2008
Balanço do Serpro 2008
Segundo entrevista com o presidente do Serviço Federal de Processamento de Dados (Serpro), o Brasil teve uma economia de R$ 30.000.000,00 (30 milhões de reais) no ano corrente (2008) apenas porque passou a adotar software livre em alguns pontos.
Durante a entrevista, foi informado que apenas com o cliente de e-mail tiveram uma economia de R$ 10.000.000,00. Imaginemos quando tiverem tirado tudo o que é software proprietário e inútil (se bem que esse implica neste) e substituído por software livre e funcional.
Pois bem, ficam a observação para os postos do governo que aindam jogam dinheiro no lixo com licenças e os parabéns para quem já aprendeu o "caminho das pedras" e mais ainda para o pessoal que está coordenando o levantamento das finanças do governo.
Isto é para mostrar a todos que software livre é funcional e economicamente viável e sustentável. Alguns anos atrás, podia ser uma utopia, mas hoje está se tornando uma realidade.
Durante a entrevista, foi informado que apenas com o cliente de e-mail tiveram uma economia de R$ 10.000.000,00. Imaginemos quando tiverem tirado tudo o que é software proprietário e inútil (se bem que esse implica neste) e substituído por software livre e funcional.
Pois bem, ficam a observação para os postos do governo que aindam jogam dinheiro no lixo com licenças e os parabéns para quem já aprendeu o "caminho das pedras" e mais ainda para o pessoal que está coordenando o levantamento das finanças do governo.
Isto é para mostrar a todos que software livre é funcional e economicamente viável e sustentável. Alguns anos atrás, podia ser uma utopia, mas hoje está se tornando uma realidade.
sexta-feira, 5 de dezembro de 2008
Carro prático
Quando eu crescer, quero ter um destes.
Mas enquanto não cresço, me contento com um modelo popular mesmo.
Mas enquanto não cresço, me contento com um modelo popular mesmo.
quinta-feira, 4 de dezembro de 2008
Smartphones com Linux
Olhem aqui.
Um post curto, pois o tempo não pára.
A Nokia anunciou que os smartphones mais modernos vão ser baseados em Linux.
Eu gostei desta notícia, pois vai ser criado um mercado de desenvolvimento de aplicações em torno destes aparelhos e as demais empresas que desenvolvem smartphones (Samsumg, LG, Motorola, Siemens, Palm, QTek, etc........) podem "entrar na onda".
Algumas empresas já tiveram experiências semelhantes, como o A1200 da Motorola.
Enfim, é algo que me agradou e eu gosto de compartilhar o que me agrada.
Um post curto, pois o tempo não pára.
A Nokia anunciou que os smartphones mais modernos vão ser baseados em Linux.
Eu gostei desta notícia, pois vai ser criado um mercado de desenvolvimento de aplicações em torno destes aparelhos e as demais empresas que desenvolvem smartphones (Samsumg, LG, Motorola, Siemens, Palm, QTek, etc........) podem "entrar na onda".
Algumas empresas já tiveram experiências semelhantes, como o A1200 da Motorola.
Enfim, é algo que me agradou e eu gosto de compartilhar o que me agrada.
segunda-feira, 1 de dezembro de 2008
Sistemas Fuzzy
Para quebrar um pouco o jejum de posts (principalmente posts sobre coisas que não sejam relacionadas a opinião pessoal) vou falar um pouco sobre sistemas Fuzzy.
Sistemas Fuzzy são baseados em lógica fuzzy (lógico) e são constituidos de 3 partes:
Descrição dos elementos do sistema fuzzy.
Para dar um exemplo, vamos supor que nós precisamos controlar o nível de água em um tanque, porém este tanque tem uma entrada de água e uma saída de água.
Vamos criar os conjuntos fuzzy das variáveis de entrada do sistema (nível do tanque e volume de água que está saindo do tanque) e da variável de saída (volume de água que está entrando no tanque).
Obs.: A variável de saída é também chamada variável de controle.
Vamos criar algumas regras fuzzy para o sistema:
O mais interessante na elaboração das regras é combinar todos os conjuntos de entrada, por exemplo (sendo x1 e x2 as variáveis de entrada e y a variável de saída):
Após a elaboração das regras, o sistema está pronto para ser implementado.
Para cada valor das variáveis de entrada, o grau de pertinência é computado e é feita uma inferência dos conjuntos fuzzy de entrada com os de saída, de modo a obter-se um conjunto fuzzy relativo a variável de saída.
Por fim, é usado algum método de desfuzzyficação para converter o conjunto fuzzy de saída em um valor numérico, como por exemplo o centro de massa do conjunto fuzzy.
Se alguém quiser, posso fazer novos posts mais detalhados.
Só para adiantar, o Scilab tem uma toolbox de lógica fuzzy (aqui).
Sistemas Fuzzy são baseados em lógica fuzzy (lógico) e são constituidos de 3 partes:
- Fuzzyficador;
- Regras e inferência;
- Desfuzzyficador.
Descrição dos elementos do sistema fuzzy.
- O Fuzzyficador consiste na interface entre as variáveis de entrada (valores numéricos) do fenômeno avaliado e o sistema fuzzy (conjuntos fuzzy).
- As regras e inferência implementam a lógica entre a entrada e a saída, gerando um conjunto fuzzy de saída.
- O Desfuzzyficador transforma o conjunto fuzzy de saída em um valor numérico.
Para dar um exemplo, vamos supor que nós precisamos controlar o nível de água em um tanque, porém este tanque tem uma entrada de água e uma saída de água.
Vamos criar os conjuntos fuzzy das variáveis de entrada do sistema (nível do tanque e volume de água que está saindo do tanque) e da variável de saída (volume de água que está entrando no tanque).
Obs.: A variável de saída é também chamada variável de controle.
Vamos criar algumas regras fuzzy para o sistema:
- Se o nível do tanque estiver baixo então tem que entrar muita água no tanque.
- Se estiver saindo pouca água do tanque e o nível estiver alto então tem que entrar pouca água no tanque.
- Se o nível da água estiver médio e estiver saindo muita água do tanque então tem que entrar muita água no tanque.
- Se o nível da água estiver alto e estiver saindo muita água do tanque então tem que entrar uma quantidade média de água no tanque.
O mais interessante na elaboração das regras é combinar todos os conjuntos de entrada, por exemplo (sendo x1 e x2 as variáveis de entrada e y a variável de saída):
- Se x1 é baixo e x2 é baixo então y é xxx.
- Se x1 é médio e x2 é baixo então y é xxx.
- Se x1 é alto e x2 é baixo então y é xxx.
- Se x1 é baixo e x2 é médio então y é xxx.
- Se x1 é médio e x2 é médio então y é xxx.
- Se x1 é alto e x2 é médio então y é xxx.
- Se x1 é baixo e x2 é alto então y é xxx.
- Se x1 é médio e x2 é alto então y é xxx.
- Se x1 é alto e x2 é alto então y é xxx.
Após a elaboração das regras, o sistema está pronto para ser implementado.
Para cada valor das variáveis de entrada, o grau de pertinência é computado e é feita uma inferência dos conjuntos fuzzy de entrada com os de saída, de modo a obter-se um conjunto fuzzy relativo a variável de saída.
Por fim, é usado algum método de desfuzzyficação para converter o conjunto fuzzy de saída em um valor numérico, como por exemplo o centro de massa do conjunto fuzzy.
Se alguém quiser, posso fazer novos posts mais detalhados.
Só para adiantar, o Scilab tem uma toolbox de lógica fuzzy (aqui).
terça-feira, 25 de novembro de 2008
Dinheiro ao Lixo no RN
Edital de prestação de contas do Cefet-RN aqui.
Um breve resumo do edital aqui.
Só para constar:
Se cada licença de antivírus for R$ 100,00 temos 1000 * R$ 100,00 = R$ 100.000,00.
Os valores que coloquei são apenas para imaginarmos quanto dinheiro público, que deveria ser revertido em benefícios para a população, é mandado para fora do país de uma forma tão estúpida.
Se fossem compradas CPUs com este dinheiro, supondo computadores de R$ 2.000,00 (muito razoáveis por sinal) era possível comprar 100 computadores.
Só com este dinheiro, seria possível construir um bloco para qualquer fim, como didático, laboratórios, administrativo, etc... (tantas vezes vi na UFC que não construiram e/ou equiparam blocos, laboratórios, escritórios, gabinetes, etc... porque acabaram os recursos financeiros).
Mas no nosso país é assim mesmo, mais vale usar o que vem de fora do que usar algo nacional, mesmo sendo de qualidade superior e custo inferior.
Um breve resumo do edital aqui.
Só para constar:
- 800 licenças - Microsoft Office;
- 1.000 liceças - Antivírus para Windows.
Se cada licença de antivírus for R$ 100,00 temos 1000 * R$ 100,00 = R$ 100.000,00.
Os valores que coloquei são apenas para imaginarmos quanto dinheiro público, que deveria ser revertido em benefícios para a população, é mandado para fora do país de uma forma tão estúpida.
Se fossem compradas CPUs com este dinheiro, supondo computadores de R$ 2.000,00 (muito razoáveis por sinal) era possível comprar 100 computadores.
Só com este dinheiro, seria possível construir um bloco para qualquer fim, como didático, laboratórios, administrativo, etc... (tantas vezes vi na UFC que não construiram e/ou equiparam blocos, laboratórios, escritórios, gabinetes, etc... porque acabaram os recursos financeiros).
Mas no nosso país é assim mesmo, mais vale usar o que vem de fora do que usar algo nacional, mesmo sendo de qualidade superior e custo inferior.
quinta-feira, 20 de novembro de 2008
Empresas na Europa, Ásia e América do Norte
Vi aqui que a crise mundial está favorecendo o software livre, como muitos já sabem, pois todas as empresas estão buscando cortar gastos desnecessários (e o que seria mais inútil que pagar pelas coisas da M$??).
Enfim, o que eu gostaria de levantar é a questão: e depois da crise? Pois com a crise atual, todos estão buscando cortar gastos (aparece com o Brasil na época do apagão em 2001 ou 2002) e depois da crise, quem vai aceitar gastar mais, apesar do dinheiro voltar a entrar normalmente? (Assim como aconteceu na época do apagão, pois muitos passaram a criar novos hábitos.)
Eu acho que os efeitos da crise no sentido de colaborar com o software livre só vão aumentar, mesmo quando a crise passar.
Eu já vi em alguns lugares, tipo a Paraíba, iniciativas do tipo: migrar todos os M$ OFFice para Open Office (ou similares) nas instituições públicas (acho que eram só as federais, mas depois as outras aprendem também).
Provavelmente, a crise ainda vai durar mais um tempinho e as suas consequências vão ficar na sociedade mundial por muito tempo e além disso, muito será feito para evitar novas crises.
Quem sabe novas crises não virão por causa da pirataria de software?
Enfim, o que eu gostaria de levantar é a questão: e depois da crise? Pois com a crise atual, todos estão buscando cortar gastos (aparece com o Brasil na época do apagão em 2001 ou 2002) e depois da crise, quem vai aceitar gastar mais, apesar do dinheiro voltar a entrar normalmente? (Assim como aconteceu na época do apagão, pois muitos passaram a criar novos hábitos.)
Eu acho que os efeitos da crise no sentido de colaborar com o software livre só vão aumentar, mesmo quando a crise passar.
Eu já vi em alguns lugares, tipo a Paraíba, iniciativas do tipo: migrar todos os M$ OFFice para Open Office (ou similares) nas instituições públicas (acho que eram só as federais, mas depois as outras aprendem também).
Provavelmente, a crise ainda vai durar mais um tempinho e as suas consequências vão ficar na sociedade mundial por muito tempo e além disso, muito será feito para evitar novas crises.
Quem sabe novas crises não virão por causa da pirataria de software?
sábado, 15 de novembro de 2008
Técnicas clássicas de segmentação de pele humana
Enfim algum tempo livre... Vou aproveitar e fazer um post sobre uma das etapas do meu mestrado a segmentação da pele.
Vou apenas apresentar 3 formas de segmentação de pele e alguns resultados obtidos.
A imagem de teste é apresentada a seguir.

Espaço de cores RGB:
Um pixel pertence a pele se satisfizer as condições abaixo:
R > 95
G > 40
B > 20
max {R, G, B} − min {R, G, B} > 15
|R − G| > 15
R>G
R>B
Resultado da segmentação:
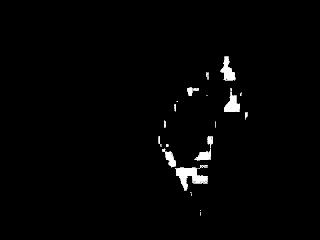
Espaço de cores YCbCr:
Um pixel pertence a pele se satisfizer as condições abaixo:
77 ≤ Cb ≤ 127
133 ≤ Cr ≤ 173
Resultado da segmentação:

Espaço de cores HSV:
Um pixel pertence a pele se satisfizer as condições abaixo:
0° ≤ H ≤ 50°
0, 23 ≤ S ≤ 0, 68
Resultado da segmentação:

Antes que alguém saia por aí dizendo que um método é melhor que outro, eu digo que depende da imagem a ser segmentada.
Os algoritmos apresentados são muito dependentes da iluminação do ambiente.
Para fechar, seguem os códigos do Scilab para segmentar imagens conforme apresentado.
/////////////////////////////////////////////////////////////////////////////////////////
// Algoritmos de segmentacao de pele em imagens baseados em limiarizacao
// Universidade Federal do Ceara
// Eng. Alex
//*//*//*//*//*//*//*//*//*//*//*//*//*//*//*//*//*//*//*//*//*//*//
//// parametros das imagens
Y = 2;
Cb = 1;
Cr = 3;
H = 1;
S = 2;
V = 3;
nL = 480; // numero de linhas da imagem
nC = 640; // numero de colunas da imagem
img = im2double(imread("imagem.jpg"));
////////////////////////////////////////
//parametros em RGB //
//////////////////////////////////////
img_s = zeros(nL, nC);
for l = 1:nL,
for c = 1:nC,
p = img(l,c,:);
ps = (p(1)>95/255).*(p(2)>40/255).*(p(3)>20/255).*(max(p) - min(p)>15/255).*(abs(p(1) - p(2))>15/255).*(p(1)==max(p));
img_s(l,c) = ps;
end;
end;
imwrite(img_s, "rgb-imagem.jpg");
///////////////////////////////////
//limiares em CbCr //
/////////////////////////////////
imgYCbCr = rgb2ycbcr(img);
img_s = double(((imgYCbCr(:,:,Cb)>76/255) .* (imgYCbCr(:,:,Cb)<128/255)).*((imgycbcr(:,:,cr)>132/255) .* (imgYCbCr(:,:,Cr)<174/255)));
imwrite(img_s, "cbcr-imagem.jpg");
///////////////////////////////
//limiares em HS //
/////////////////////////////
imgHSV = rgb2hsv(img);
img_s = double((imgHSV(:,:,H)<50/360).*((imghsv(:,:,s)>0.23) .* (imgHSV(:,:,S)<0.68)));
imwrite(img_s, "hs-imagem.jpg");
Vou apenas apresentar 3 formas de segmentação de pele e alguns resultados obtidos.
A imagem de teste é apresentada a seguir.

Espaço de cores RGB:
Um pixel pertence a pele se satisfizer as condições abaixo:
R > 95
G > 40
B > 20
max {R, G, B} − min {R, G, B} > 15
|R − G| > 15
R>G
R>B
Resultado da segmentação:

Espaço de cores YCbCr:
Um pixel pertence a pele se satisfizer as condições abaixo:
77 ≤ Cb ≤ 127
133 ≤ Cr ≤ 173
Resultado da segmentação:

Espaço de cores HSV:
Um pixel pertence a pele se satisfizer as condições abaixo:
0° ≤ H ≤ 50°
0, 23 ≤ S ≤ 0, 68
Resultado da segmentação:

Antes que alguém saia por aí dizendo que um método é melhor que outro, eu digo que depende da imagem a ser segmentada.
Os algoritmos apresentados são muito dependentes da iluminação do ambiente.
Para fechar, seguem os códigos do Scilab para segmentar imagens conforme apresentado.
/////////////////////////////////////////////////////////////////////////////////////////
// Algoritmos de segmentacao de pele em imagens baseados em limiarizacao
// Universidade Federal do Ceara
// Eng. Alex
//*//*//*//*//*//*//*//*//*//*//*//*//*//*//*//*//*//*//*//*//*//*//
//// parametros das imagens
Y = 2;
Cb = 1;
Cr = 3;
H = 1;
S = 2;
V = 3;
nL = 480; // numero de linhas da imagem
nC = 640; // numero de colunas da imagem
img = im2double(imread("imagem.jpg"));
////////////////////////////////////////
//parametros em RGB //
//////////////////////////////////////
img_s = zeros(nL, nC);
for l = 1:nL,
for c = 1:nC,
p = img(l,c,:);
ps = (p(1)>95/255).*(p(2)>40/255).*(p(3)>20/255).*(max(p) - min(p)>15/255).*(abs(p(1) - p(2))>15/255).*(p(1)==max(p));
img_s(l,c) = ps;
end;
end;
imwrite(img_s, "rgb-imagem.jpg");
///////////////////////////////////
//limiares em CbCr //
/////////////////////////////////
imgYCbCr = rgb2ycbcr(img);
img_s = double(((imgYCbCr(:,:,Cb)>76/255) .* (imgYCbCr(:,:,Cb)<128/255)).*((imgycbcr(:,:,cr)>132/255) .* (imgYCbCr(:,:,Cr)<174/255)));
imwrite(img_s, "cbcr-imagem.jpg");
///////////////////////////////
//limiares em HS //
/////////////////////////////
imgHSV = rgb2hsv(img);
img_s = double((imgHSV(:,:,H)<50/360).*((imghsv(:,:,s)>0.23) .* (imgHSV(:,:,S)<0.68)));
imwrite(img_s, "hs-imagem.jpg");
terça-feira, 11 de novembro de 2008
Chegando na reta final da qualificação
Aos leitores do MultiSign que percebem minha ausência nos posts, informo que a previsão é que na próxima semana eu volte a atualizar o blog com mais frequência.
Se bem que poucas pessoas interagem com comentários e a enquete.
Vejo no mapa um monte de pontos enormes sobre o Brasil (o que indica centenas de leitores), mas poucos são os que comentam (não tenho nenhum post nem com 5 comentários) e eu vejo blogs por aí que todos os posts têm dezenas de comentários.
Mas enfim, não deixarei de fazer os posts porque meus leitores não comentam, porém se comentassem, ajudaria bastante.
E só para adiantar, os resultados que estou tendo nos testes preliminares são motivadores.
Esperem e verão.
Se bem que poucas pessoas interagem com comentários e a enquete.
Vejo no mapa um monte de pontos enormes sobre o Brasil (o que indica centenas de leitores), mas poucos são os que comentam (não tenho nenhum post nem com 5 comentários) e eu vejo blogs por aí que todos os posts têm dezenas de comentários.
Mas enfim, não deixarei de fazer os posts porque meus leitores não comentam, porém se comentassem, ajudaria bastante.
E só para adiantar, os resultados que estou tendo nos testes preliminares são motivadores.
Esperem e verão.
sábado, 8 de novembro de 2008
Fuzzy Logic
The fuzzy logic is a generalization of classic sets theory.
In the classic sets theory, a element is in a set or not.
For example, the fruit's universe, the orange is in set of citric fruits, and the apple is not in that set.
But, if we analyze the people's universe and make 2 sets: rich people and poor people. If anyone has more than US$ 500,000.00, that's rich, if anyone has less than US$ 500,000.00, that's poor.
Thus, someone has US$10,000.00; US$30,000.00; US$50,000.00; US$70,000.00; US$100,000.00; US$120,000.00; US$180,000.00; US$210,000.00; US$220,000.00; US$300,000.00; US$450,000.00; US$480,000.00; US$492,000.00; US$497,000.00; US$499,800.00; US$499,930.00; US$499,981.00; US$499,996.00; US$499,999.20; US$499,999.98; that's a poor people. And other someone has US$1,000,000.00; US$980,000.00; US$840,000.00; US$770,000.00; US$680,000.00; US$610,000.00; US$590,000.00; US$540,000.00; US$510,000.00; US$508,000.00; US$502,000.00; US$501,000.00; US$500,100.00; US$500,010.00; US$500,001.00; US$500,000.10; that's a rich people.
But, let's think: if anyone has US$499,999.97 and other one has US$500,000.01 they have the same money, because US$0.04 is almost no money, but they aren't in same set.
The fuzzy logic add the pertinence concept for each element. So, all elements are in all sets, but each element has a specific pertinence in each set.
We can use fuzzy logic in any situation, solving it as a linguistic problem. If you need classify the cars in big or small, is possible do 2 fuzzy sets, if you need classify the cars in big, small and median, is possible do 3 fuzzy sets, and successively.
I did the following video of a application that I developed for A.I. class.
Any question, you can comment the post.
In the classic sets theory, a element is in a set or not.
For example, the fruit's universe, the orange is in set of citric fruits, and the apple is not in that set.
But, if we analyze the people's universe and make 2 sets: rich people and poor people. If anyone has more than US$ 500,000.00, that's rich, if anyone has less than US$ 500,000.00, that's poor.
Thus, someone has US$10,000.00; US$30,000.00; US$50,000.00; US$70,000.00; US$100,000.00; US$120,000.00; US$180,000.00; US$210,000.00; US$220,000.00; US$300,000.00; US$450,000.00; US$480,000.00; US$492,000.00; US$497,000.00; US$499,800.00; US$499,930.00; US$499,981.00; US$499,996.00; US$499,999.20; US$499,999.98; that's a poor people. And other someone has US$1,000,000.00; US$980,000.00; US$840,000.00; US$770,000.00; US$680,000.00; US$610,000.00; US$590,000.00; US$540,000.00; US$510,000.00; US$508,000.00; US$502,000.00; US$501,000.00; US$500,100.00; US$500,010.00; US$500,001.00; US$500,000.10; that's a rich people.
But, let's think: if anyone has US$499,999.97 and other one has US$500,000.01 they have the same money, because US$0.04 is almost no money, but they aren't in same set.
The fuzzy logic add the pertinence concept for each element. So, all elements are in all sets, but each element has a specific pertinence in each set.
We can use fuzzy logic in any situation, solving it as a linguistic problem. If you need classify the cars in big or small, is possible do 2 fuzzy sets, if you need classify the cars in big, small and median, is possible do 3 fuzzy sets, and successively.
I did the following video of a application that I developed for A.I. class.
Any question, you can comment the post.
quinta-feira, 6 de novembro de 2008
Lógica Fuzzy
Lógica Fuzzy é uma generalização da teoria dos conjuntos clássica.
Na teoria dos conjuntos clássica, se eu tiver um determinado elemento, este elemento pode pertencer ou não a um determinado conjunto.
Por exemplo, tomando o universo das frutas, a tangerina pertence ao conjunto das frutas cítricas. A maçã não pertence ao conjunto das frutas cítricas.
Mas se tomarmos o universo das pessoas, vamos classificar as pessoas em ricas e pobres. Como critério vamos tomar o patrimônio de cada pessoa e determinar que pessoas com patrimônio acima de R$500.000,00 sejam ricas e abaixo sejam pobres, então pessoas com patrimônios de R$10.000,00; R$30.000,00; R$50.000,00; R$70.000,00; R$100.000,00; R$120.000,00; R$180.000,00; R$210.000,00; R$220.000,00; R$300.000,00; R$450.000,00; R$480.000,00; R$492.000,00; R$497.000,00; R$499.800,00; R$499.930,00; R$499.981,00; R$499.996,00; R$499.999,20; R$499.999,98 seriam pobres e pessoas com patrimônios de R$1.000.000,00; R$980.000,00; R$840.000,00; R$770.000,00; R$680.000,00; R$610.000,00; R$590.000,00; R$540.000,00; R$510.000,00; R$508.000,00; R$502.000,00; R$501.000,00; R$500.100,00; R$500.010,00; R$500.001,00; R$500.000,10 seriam ricas. Mas qual a diferença de padrimônio entre R$500.000,02 e R$499.999,97? Isto não vale nem um pirulito que vendem nas paradas de ônibus, algumas vezes nem dão o troco menor que R$0,10.
Então, para resolver o problema, a lógica fuzzy incorpora o conceito de pertinência. De modo que todos os elementos pertencem a todos os conjuntos, porém pertencem mais ou menos a um determinado conjunto.
Uma aplicação interessante da lógica fuzzy e que é presente em nosso cotidiano são os aparelhos de ar-condicionado, que têm algoritmos de lógica fuzzy embarcados para o controle da temperatura, assim evitando que a chave fique disparando toda hora, e considerando que o disparo da chave é o que gasta mais energia no aparelho de ar-condicionado, isto implica em uma economia muito considerável, por isto também que estes são os aparelhos com selo de economia de energia.
Segue um vídeo que mostra uma aplicação que fiz usando lógica fuzzy para controlar um foguete.
Na teoria dos conjuntos clássica, se eu tiver um determinado elemento, este elemento pode pertencer ou não a um determinado conjunto.
Por exemplo, tomando o universo das frutas, a tangerina pertence ao conjunto das frutas cítricas. A maçã não pertence ao conjunto das frutas cítricas.
Mas se tomarmos o universo das pessoas, vamos classificar as pessoas em ricas e pobres. Como critério vamos tomar o patrimônio de cada pessoa e determinar que pessoas com patrimônio acima de R$500.000,00 sejam ricas e abaixo sejam pobres, então pessoas com patrimônios de R$10.000,00; R$30.000,00; R$50.000,00; R$70.000,00; R$100.000,00; R$120.000,00; R$180.000,00; R$210.000,00; R$220.000,00; R$300.000,00; R$450.000,00; R$480.000,00; R$492.000,00; R$497.000,00; R$499.800,00; R$499.930,00; R$499.981,00; R$499.996,00; R$499.999,20; R$499.999,98 seriam pobres e pessoas com patrimônios de R$1.000.000,00; R$980.000,00; R$840.000,00; R$770.000,00; R$680.000,00; R$610.000,00; R$590.000,00; R$540.000,00; R$510.000,00; R$508.000,00; R$502.000,00; R$501.000,00; R$500.100,00; R$500.010,00; R$500.001,00; R$500.000,10 seriam ricas. Mas qual a diferença de padrimônio entre R$500.000,02 e R$499.999,97? Isto não vale nem um pirulito que vendem nas paradas de ônibus, algumas vezes nem dão o troco menor que R$0,10.
Então, para resolver o problema, a lógica fuzzy incorpora o conceito de pertinência. De modo que todos os elementos pertencem a todos os conjuntos, porém pertencem mais ou menos a um determinado conjunto.
Uma aplicação interessante da lógica fuzzy e que é presente em nosso cotidiano são os aparelhos de ar-condicionado, que têm algoritmos de lógica fuzzy embarcados para o controle da temperatura, assim evitando que a chave fique disparando toda hora, e considerando que o disparo da chave é o que gasta mais energia no aparelho de ar-condicionado, isto implica em uma economia muito considerável, por isto também que estes são os aparelhos com selo de economia de energia.
Segue um vídeo que mostra uma aplicação que fiz usando lógica fuzzy para controlar um foguete.
segunda-feira, 3 de novembro de 2008
Crianças com futuro
Olhem aqui e pensem.
Espero que tenham olhado e, principalmente, pensado.
Se crianças de 8 anos de idade têm consiência que usar Linux é melhor sem, provavelmente, nem saber a respeito de filosofia open-source e tudo o que implica o software livre.
As crianças apenas experimentaram ambos e disseram: "prefiro este!", lógico que eles pensaram em qual dos sistemas tinha mais aplicativos interessantes (tipo jogos), qual era mais fácil de usar (interface mais amigável), e demais coisas do tipo.
Eu espero que nossos adultos aprendam com estas crianças e que as crianças tornem-se adultos coerentes.
Espero que tenham olhado e, principalmente, pensado.
Se crianças de 8 anos de idade têm consiência que usar Linux é melhor sem, provavelmente, nem saber a respeito de filosofia open-source e tudo o que implica o software livre.
As crianças apenas experimentaram ambos e disseram: "prefiro este!", lógico que eles pensaram em qual dos sistemas tinha mais aplicativos interessantes (tipo jogos), qual era mais fácil de usar (interface mais amigável), e demais coisas do tipo.
Eu espero que nossos adultos aprendam com estas crianças e que as crianças tornem-se adultos coerentes.
domingo, 2 de novembro de 2008
Vowels in Sign Language
I recorded some videos more to my mastering qualify (the alphabet in Libras - Brazilian Sign Language).
I'm having problems with the Scilab (it doesn't read the videos), thus I used the mplayer to extract the frames. For extract frames from a video, I use the command:
>> mplayer -vo jpeg name_of_the_file.avi
Now, I'm doing tests about skin segmentation. I tried threshold and clustering algorithms, but nothing works with all pictures that I have.
If anyone can helps me, I will be very grateful.
These are some pictures that I have:

Letter 'A':


Letter 'E':


Letter 'I':


Letter 'O':


Letter 'U':


I'm having problems with the Scilab (it doesn't read the videos), thus I used the mplayer to extract the frames. For extract frames from a video, I use the command:
>> mplayer -vo jpeg name_of_the_file.avi
Now, I'm doing tests about skin segmentation. I tried threshold and clustering algorithms, but nothing works with all pictures that I have.
If anyone can helps me, I will be very grateful.
These are some pictures that I have:
Letter 'A':


Letter 'E':


Letter 'I':


Letter 'O':


Letter 'U':


Vogais em Libras
Eu fiz mais uns vídeos para a minha qualificação de mestrado.
Como eu estou com problemas com o Scilab (que decidiu não abrir mais arquivos de vídeo) eu extrai os frames de cada vídeo (com o mplayer), basta dar o comando:
>> mplayer -vo jpeg nome_do_arquivo.avi
Atualmente, estou avaliando algoritmos de segmentação da pele, testei alguns de limiarização e outros baseados em clustering. Nenhum deles funciona bem em todas as imagens que tenho, caso alguém se disponha a ajudar, ficarei muito grato.
Seguem algumas imagens que gerei.
Letra 'A'


Letra 'E'


Letra 'I'


Letra 'O'


Letra 'U'


Como eu estou com problemas com o Scilab (que decidiu não abrir mais arquivos de vídeo) eu extrai os frames de cada vídeo (com o mplayer), basta dar o comando:
>> mplayer -vo jpeg nome_do_arquivo.avi
Atualmente, estou avaliando algoritmos de segmentação da pele, testei alguns de limiarização e outros baseados em clustering. Nenhum deles funciona bem em todas as imagens que tenho, caso alguém se disponha a ajudar, ficarei muito grato.
Seguem algumas imagens que gerei.
Letra 'A'


Letra 'E'


Letra 'I'


Letra 'O'


Letra 'U'


quarta-feira, 29 de outubro de 2008
Converter todas as imagens de um diretório
Um post bem curto, para variar um pouco.
Vi este link e achei interessante.
Tudo consiste neste script (para rodar no shell do Linux):
>> for f in *.jpg;
>> do convert -verbose $f ${f%.*}.png;
>> done
O comando convert pertence ao pacote do ImageMagick.
O código apresentado converte todas as imagens do diretório corrente de *.jpg para *.png, para converter entre outros formatos basta mudar para as extensões desejadas.
Para os que não compreenderam o código:
1a linha - laço que percorre todos os arquivos de extensão *.jpg;
2a linha - chama o convert para mudar o arquivo atual $f para o novo arquivo, que terá o mesmo nome com a nova extensão ${f%.*}.png;
3a linha - indica o fim do laço.
Os que entendem algo de codificação de imagens, devem imaginar os benefícios que este tipo de recurso oferece.
Vi este link e achei interessante.
Tudo consiste neste script (para rodar no shell do Linux):
>> for f in *.jpg;
>> do convert -verbose $f ${f%.*}.png;
>> done
O comando convert pertence ao pacote do ImageMagick.
O código apresentado converte todas as imagens do diretório corrente de *.jpg para *.png, para converter entre outros formatos basta mudar para as extensões desejadas.
Para os que não compreenderam o código:
1a linha - laço que percorre todos os arquivos de extensão *.jpg;
2a linha - chama o convert para mudar o arquivo atual $f para o novo arquivo, que terá o mesmo nome com a nova extensão ${f%.*}.png;
3a linha - indica o fim do laço.
Os que entendem algo de codificação de imagens, devem imaginar os benefícios que este tipo de recurso oferece.
terça-feira, 28 de outubro de 2008
Auto-Linux
Olhem esta notícia.
Não é maravilhoso saber que empresas do porte da BMW e da GM estão investindo em sistemas open-source (Linux based) em seus veículos?
E quanto as novas possibilidades? Para as pessoas que têm condições de desenvolver software, poderemos ter pessoas desenvolvendo softwares para seus próprios carros.
E o novo mercado de negócios: desenvolvimento de software automotivo.
Poderão surgir novas empresas para desenvolver os sistemas para os carros com Linux embarcado, bastando para isto que os desenvolvedores conheçam o S. O. que está rodando, o qual é open-source, então basta pegar na web.
Para os interessado em aplicações mais avançadas, tipo eu, por exemplo: sistemas de reconhecimento de padrões, processamento digital de sinais e imagens, automação, etc.... as oportunidades serão muitas.
Enfim, eu queria só partilhar um pouco da felicidade que tive ao ler esta notícia.
Não é maravilhoso saber que empresas do porte da BMW e da GM estão investindo em sistemas open-source (Linux based) em seus veículos?
E quanto as novas possibilidades? Para as pessoas que têm condições de desenvolver software, poderemos ter pessoas desenvolvendo softwares para seus próprios carros.
E o novo mercado de negócios: desenvolvimento de software automotivo.
Poderão surgir novas empresas para desenvolver os sistemas para os carros com Linux embarcado, bastando para isto que os desenvolvedores conheçam o S. O. que está rodando, o qual é open-source, então basta pegar na web.
Para os interessado em aplicações mais avançadas, tipo eu, por exemplo: sistemas de reconhecimento de padrões, processamento digital de sinais e imagens, automação, etc.... as oportunidades serão muitas.
Enfim, eu queria só partilhar um pouco da felicidade que tive ao ler esta notícia.
segunda-feira, 27 de outubro de 2008
Genetic Algorithms
I'll talk about Genetic Algorithms at this post.
Genetics Algorithms (G. A.) are a type of evolutionary computation, wich the software "upgrade itself" for solve a problem.
The principle of G. A. is the Theory of Evolution (Biology).
In terms of system's engineering, we use G. A. with 4 steps:
Observations:
A example: give a room with N lamps, which lamps should be lit for best lighting and less power consume?
{Making N = 10}
Each possible solution is a 10 positions vector: s = [l0 l1 l2 l3 l4 l5 l6 l7 l8 l9] which s[i] indicates the status of i-st lamp (s[i] = 1 -> lamp on, s[i] = 0 -> lamp off).
Creating a population of solutions:
s1 = [0 1 1 0 0 0 1 1 1 1]
s2 = [0 1 0 0 1 1 0 1 1 0]
s3 = [1 1 0 1 1 0 0 0 1 0]
s4 = [0 0 0 0 1 1 1 1 1 0]
(Of course that's very few solutions.)
Let's suppose that:
G(s1) = 18%
G(s2) = 32%
G(s3) = 35%
G(s4) = 15%
(The developer invents the G(.) according the problem.)
Thus, in this case, the result of G(.) is the probability of each solution cross with other solution.
(Is not possible make a "self-cross")
One very possible crossing is {s1, s3}.
s1= [0 1 1 0 0 0 1 1 1 1] and s3 = [1 1 0 1 1 0 0 0 1 0]
Determine a random point in the vector (for example 6) and change the numbers.
The cross' result:
s1' = [s1[0] s1[1] s1[2] s1[3] s1[4] s1[5] s3[6] s3[7] s3[8] s3[9]]
s1' = [0 1 1 0 0 0 0 0 1 0]
s2' = [s3[0] s3[1] s3[2] s3[3] s3[4] s3[5] s1[6] s1[7] s1[8] s1[9]]
s2' = [1 1 0 1 1 0 1 1 1 1]
So, the function G(.) is used in all new solutions, and the cross occurs until find a good solution.
I explained a simple form of develop a genetic algorithm, but the algorithm's complexity can be higher if you use many points in the cross, non-binaries vectors or insert mutation in the algorithm (if the algorithm don't result to good solutions).
Now, let's play with the Genetic Algorithms.
Genetics Algorithms (G. A.) are a type of evolutionary computation, wich the software "upgrade itself" for solve a problem.
The principle of G. A. is the Theory of Evolution (Biology).
In terms of system's engineering, we use G. A. with 4 steps:
- Identify the problem and make it solution as a vector of numbers (preferentially, binary numbers);
- Generate a lot of possible solutions (population), without think "what's the best solution for my problem?" (the software will find a good solution);
- Create a measure for the solutions (G(.)), this measure indicates the "solution's adaptability" (for each solution);
- Cross the solutions until a satisfiable solution is find.
Observations:
- The more adaptable solutions have more probability of cross with others solution.
- The function G(.) is higher as better is the solution for solve the problem.
- The cross between 2 solutions occurs with a changing of some numbers of the vectors.
- The worst solutions are discarded and the new solutions just be better than the old solutions.
A example: give a room with N lamps, which lamps should be lit for best lighting and less power consume?
{Making N = 10}
Each possible solution is a 10 positions vector: s = [l0 l1 l2 l3 l4 l5 l6 l7 l8 l9] which s[i] indicates the status of i-st lamp (s[i] = 1 -> lamp on, s[i] = 0 -> lamp off).
Creating a population of solutions:
s1 = [0 1 1 0 0 0 1 1 1 1]
s2 = [0 1 0 0 1 1 0 1 1 0]
s3 = [1 1 0 1 1 0 0 0 1 0]
s4 = [0 0 0 0 1 1 1 1 1 0]
(Of course that's very few solutions.)
Let's suppose that:
G(s1) = 18%
G(s2) = 32%
G(s3) = 35%
G(s4) = 15%
(The developer invents the G(.) according the problem.)
Thus, in this case, the result of G(.) is the probability of each solution cross with other solution.
(Is not possible make a "self-cross")
One very possible crossing is {s1, s3}.
s1= [0 1 1 0 0 0 1 1 1 1] and s3 = [1 1 0 1 1 0 0 0 1 0]
Determine a random point in the vector (for example 6) and change the numbers.
The cross' result:
s1' = [s1[0] s1[1] s1[2] s1[3] s1[4] s1[5] s3[6] s3[7] s3[8] s3[9]]
s1' = [0 1 1 0 0 0 0 0 1 0]
s2' = [s3[0] s3[1] s3[2] s3[3] s3[4] s3[5] s1[6] s1[7] s1[8] s1[9]]
s2' = [1 1 0 1 1 0 1 1 1 1]
So, the function G(.) is used in all new solutions, and the cross occurs until find a good solution.
I explained a simple form of develop a genetic algorithm, but the algorithm's complexity can be higher if you use many points in the cross, non-binaries vectors or insert mutation in the algorithm (if the algorithm don't result to good solutions).
Now, let's play with the Genetic Algorithms.
terça-feira, 21 de outubro de 2008
Feed
I maked this post for report to the reader that don't have many free time.
The Feeds (here is a text about it - in portuguese) enable that the reader knows the posts without visits the blog/site.
The RSS is the principle of feeds's operation. All's blogs have (or should have) it RSS available.
To acess the RSS content consists in add the RSS adress in a RSS reader, it can be on-line (for example My Yahoo!, Google, others blogs/sites) or locals (Akregator, for example).
For finish, these are MultiSign's adresses for some services:
The Feeds (here is a text about it - in portuguese) enable that the reader knows the posts without visits the blog/site.
The RSS is the principle of feeds's operation. All's blogs have (or should have) it RSS available.
To acess the RSS content consists in add the RSS adress in a RSS reader, it can be on-line (for example My Yahoo!, Google, others blogs/sites) or locals (Akregator, for example).
For finish, these are MultiSign's adresses for some services:
Acompanhe o MultiSign
Vou dar uma sugestão para quem gosta de acompanhar o que está dando nos blogs mas não deseja passar muito tempo olhando os blogs um a um.
Os Feeds (aqui tem um texto que fiz a respeito) possibilitam que o leitor tome conhecimento do que foi postado no blog sem a necessidade de visitar o blog.
O RSS é o princípio de funcionamento dos feeds e todo blog tem (ou deveria ter) seu RSS disponível.
Para ter acesso ao conteúdo RSS de um blog basta adicionar o endereço de RSS deste blog em um leitor de RSS, neste post faço uma citação de como funciona.
Como exemplo de leitor de RSS, posso citar o Akregator.
Existem também leitores de RSS on-line, como o que eu faço aqui no MultiSign (no final da página).
Para fechar, seguem os endereços de RSS do MultiSign para os diversos serviços on-line:
Os Feeds (aqui tem um texto que fiz a respeito) possibilitam que o leitor tome conhecimento do que foi postado no blog sem a necessidade de visitar o blog.
O RSS é o princípio de funcionamento dos feeds e todo blog tem (ou deveria ter) seu RSS disponível.
Para ter acesso ao conteúdo RSS de um blog basta adicionar o endereço de RSS deste blog em um leitor de RSS, neste post faço uma citação de como funciona.
Como exemplo de leitor de RSS, posso citar o Akregator.
Existem também leitores de RSS on-line, como o que eu faço aqui no MultiSign (no final da página).
Para fechar, seguem os endereços de RSS do MultiSign para os diversos serviços on-line:
segunda-feira, 20 de outubro de 2008
Conjunto de vídeos sobre Libras
Hoje eu fiz os primeiros vídeos para testar os algoritmos que desenvolvi para o meu mestrado.
Primeiro vou testar algoritmos de segmentação, depois de extração dos momentos centrados e por fim os algoritmos de classificação.
Eu fiz um código do Scilab para fazer a captura do vídeo, como o que apresentei aqui.
Eu fiz 2 conjuntos de vídeos com as 26 letras do alfabeto em Libras (um vídeo por letra).
Pelo que vi nos vídeos, terei problemas em fazer a segmentação da mão, caso seja necessário, e/ou algoritmos de rastreamento.
Eu fiz os vídeos na Feneis-CE com 2 pessoas que têm experiência com Libras (um deles é deficiente auditivo).
Sobre os vídeos, eu os fiz com uma webcam VGA (640 x 480 pixels) com duração de 5 segundos a 20 fps.
Eu pensei em fornecer os vídeos a possíveis colaboradores que tenham interesse em trabalhar com reconhecimento de gestos ou mesmo com o reconhecimento da Libras.
Como são muitos vídeos (52 no total) eu não acho interessante colocá-los no YouTube, mas posso passar por e-mail aos interessados (cada conjunto de vídeos tem uns 13,5 MB).
Os interessados podem deixar seus dados (nome e e-mail) como comentário que eu mando os arquivos.
Primeiro vou testar algoritmos de segmentação, depois de extração dos momentos centrados e por fim os algoritmos de classificação.
Eu fiz um código do Scilab para fazer a captura do vídeo, como o que apresentei aqui.
Eu fiz 2 conjuntos de vídeos com as 26 letras do alfabeto em Libras (um vídeo por letra).
Pelo que vi nos vídeos, terei problemas em fazer a segmentação da mão, caso seja necessário, e/ou algoritmos de rastreamento.
Eu fiz os vídeos na Feneis-CE com 2 pessoas que têm experiência com Libras (um deles é deficiente auditivo).
Sobre os vídeos, eu os fiz com uma webcam VGA (640 x 480 pixels) com duração de 5 segundos a 20 fps.
Eu pensei em fornecer os vídeos a possíveis colaboradores que tenham interesse em trabalhar com reconhecimento de gestos ou mesmo com o reconhecimento da Libras.
Como são muitos vídeos (52 no total) eu não acho interessante colocá-los no YouTube, mas posso passar por e-mail aos interessados (cada conjunto de vídeos tem uns 13,5 MB).
Os interessados podem deixar seus dados (nome e e-mail) como comentário que eu mando os arquivos.
sábado, 18 de outubro de 2008
Editor de legendas
Eu estava procurando um editor de legendas no Synaptic e achei o Subtitle Editor.
Eu havia achado outros mas não funcionaram bem e o Subtitle Editor além de simples e intuitivo é muito estável.
Segue a tela inicial do aplicativo.

Como pode-se ver, ele tem também o recurso de carregar o vídeo e ver como está a legenda.
A imagem a seguir mostra o Subtitle Editor com uma legenda carregada.

Para finalizar, a mesma conversa de sempre: o Subtitle Editor é um software livre e quem trabalha com edição de vídeo tem uma opção de desenvolver seu trabalho de forma legal e sem nenhum custo com software.
Eu havia achado outros mas não funcionaram bem e o Subtitle Editor além de simples e intuitivo é muito estável.
Segue a tela inicial do aplicativo.

Como pode-se ver, ele tem também o recurso de carregar o vídeo e ver como está a legenda.
A imagem a seguir mostra o Subtitle Editor com uma legenda carregada.

Para finalizar, a mesma conversa de sempre: o Subtitle Editor é um software livre e quem trabalha com edição de vídeo tem uma opção de desenvolver seu trabalho de forma legal e sem nenhum custo com software.
terça-feira, 14 de outubro de 2008
Image processing in batch
I don't have very free time (because I'm doing my mastering qualify), thus this post will be small.
I want show the Phatch.
It's a software for image processing in batch. I don't know how that works, but I believe that it makes the same processing for all images (in a sequence).
Some examples of operations in the Phatch:
The Phatch has more complex operations, but I don't use it yet, so I cann't talk about them.
I want show the Phatch.
It's a software for image processing in batch. I don't know how that works, but I believe that it makes the same processing for all images (in a sequence).
Some examples of operations in the Phatch:
- Resize;
- Water mark;
- Smoothing of boundaries;
- Rotate.
The Phatch has more complex operations, but I don't use it yet, so I cann't talk about them.
domingo, 12 de outubro de 2008
Processamento de imagens em lote
Como vocês sabem, o tempo é curto e por isso esta postagem também o será.
É só para apresentar o Phatch.
Trata-se de um software para tratamento de imagens em lote. Acredito que o tratamento em lote consiste em ter uma sequência de imagens e fazer a mesma operação sobre todas elas.
Exemplos de operações que eu vi no Phatch:
Como disse, estes são exemplos de recursos do Phatch.
É só para apresentar o Phatch.
Trata-se de um software para tratamento de imagens em lote. Acredito que o tratamento em lote consiste em ter uma sequência de imagens e fazer a mesma operação sobre todas elas.
Exemplos de operações que eu vi no Phatch:
- Redimensionamento;
- Marca d'água;
- Arredondamento de bordas;
- Rotação.
Como disse, estes são exemplos de recursos do Phatch.
quinta-feira, 9 de outubro de 2008
Qualification
I was told that I have 1 month to complete my mastering qualification.
Thus, I can't make posts frequently until the next month.
But, I want to thank to readers who visited the MultiSign (yesterday I had 37 visits, see here). I'm very happy too because I saw the first place with more than 10 visits out of Brazil and Portugual, look the picture.

See the west of United States (the left side).
So, it's all.
Thus, I can't make posts frequently until the next month.
But, I want to thank to readers who visited the MultiSign (yesterday I had 37 visits, see here). I'm very happy too because I saw the first place with more than 10 visits out of Brazil and Portugual, look the picture.

See the west of United States (the left side).
So, it's all.
Qualificação
Esta semana eu descobri que tenho 1 mês para preparar toda a minha qualificação de mestrado.
Por isto eu não poderei manter o MultiSign atualizado com frequência.
Eu agradeço aos leitores que lêem o blog com frequência (ontem mesmo tive 37 visitas, olhem aqui) e algo que me deixou muito satisfeito foi o primeiro ponto com mais de 10 visitas fora do Brasil e Portugual, conforme a figura abaixo.

Olhem o oeste (lado esquerdo) dos Estados Unidos.
Enfim, é só isso mesmo.
Por isto eu não poderei manter o MultiSign atualizado com frequência.
Eu agradeço aos leitores que lêem o blog com frequência (ontem mesmo tive 37 visitas, olhem aqui) e algo que me deixou muito satisfeito foi o primeiro ponto com mais de 10 visitas fora do Brasil e Portugual, conforme a figura abaixo.

Olhem o oeste (lado esquerdo) dos Estados Unidos.
Enfim, é só isso mesmo.
terça-feira, 7 de outubro de 2008
Dicas para concursos
Hoje vi este vídeo com dicas para concursos, em especial na parte de legislação.
Como os concursos públicos são muito visados atualmente (eu mesmo, talvez, preste concursos no futuro) e em todos os concursos têm muitas questões de legislação (até os engenheiros e cientistas da computação precisam fazer provas de decorar as leis), que eu particularmente tenho problemas pois minha memória não vale muito, eu achei que seria interessante fazer este post.
Pois é, quem for fazer concursos deve estudar 2 vezes muito:
1a. - Para passar no concurso.
2a. - Para aprender o necessário e desempenhar suas funções da melhor forma possível.
Como os concursos públicos são muito visados atualmente (eu mesmo, talvez, preste concursos no futuro) e em todos os concursos têm muitas questões de legislação (até os engenheiros e cientistas da computação precisam fazer provas de decorar as leis), que eu particularmente tenho problemas pois minha memória não vale muito, eu achei que seria interessante fazer este post.
Pois é, quem for fazer concursos deve estudar 2 vezes muito:
1a. - Para passar no concurso.
2a. - Para aprender o necessário e desempenhar suas funções da melhor forma possível.
sexta-feira, 3 de outubro de 2008
Celular com raio-x
Hoje vi esta notícia e achei muito interessante.
Trata-se de um software que vai usar GPS, sensores geomagnéticos e de aceleração e outros recursos a mais para "ver atraveś" das paredes.
A idéia, pelo que entendi, é a seguinte:
Primeiro toma-se conhecimento de todos os pontos (cômodos) de todas a infraestrutura (casas, prédios, ruas, etc....) de onde se encontra o usuário. Os sensores vão determinar a posição e para onde o celular está sendo apontado, aí é só fazer um modelo 3D (vão usar OpenGL para fazer o modelo) e simular que o celular tem uma câmera que "vê" através da parede.
Neste caso, a visão pode ser de coisas muito mais distântes, pois basta acessar a informação e criar o modelo, de modo que é possível ver através de várias paredes ao mesmo tempo.
Trata-se de um software que vai usar GPS, sensores geomagnéticos e de aceleração e outros recursos a mais para "ver atraveś" das paredes.
A idéia, pelo que entendi, é a seguinte:
Primeiro toma-se conhecimento de todos os pontos (cômodos) de todas a infraestrutura (casas, prédios, ruas, etc....) de onde se encontra o usuário. Os sensores vão determinar a posição e para onde o celular está sendo apontado, aí é só fazer um modelo 3D (vão usar OpenGL para fazer o modelo) e simular que o celular tem uma câmera que "vê" através da parede.
Neste caso, a visão pode ser de coisas muito mais distântes, pois basta acessar a informação e criar o modelo, de modo que é possível ver através de várias paredes ao mesmo tempo.
quarta-feira, 1 de outubro de 2008
Control the ball with your hands - Game
Using the segmentation of hands, I developed the game Control the ball with your hands.
This a video for show the game:
This game was developed in the Scilab, using the SIVP toolbox, thus it's a simulation algorithm.
I develop games like this because I like it.
If anyone wants talk about this game, or others things, may send me e-mails.
This a video for show the game:
This game was developed in the Scilab, using the SIVP toolbox, thus it's a simulation algorithm.
I develop games like this because I like it.
If anyone wants talk about this game, or others things, may send me e-mails.
terça-feira, 30 de setembro de 2008
Neural Segmentation of Hands
I developed an algorithm for segmentation of objects in digital images.
I maked this algorithm because I will need do segmentation of hand in my mastering project.
This a video whose I do for show the result.
The algorithm consists in build 2 clusters, the first for mapping the object and the second for mapping the ground.
I used Self-Organizing Maps for build the clusters.
I wrote the code in Scilab, using the SIVP toolbox.
I maked this algorithm because I will need do segmentation of hand in my mastering project.
This a video whose I do for show the result.
The algorithm consists in build 2 clusters, the first for mapping the object and the second for mapping the ground.
I used Self-Organizing Maps for build the clusters.
I wrote the code in Scilab, using the SIVP toolbox.
segunda-feira, 29 de setembro de 2008
PageRank - Google
O PageRank (ou aqui) de um site é um número (inteiro) de 0 a 10 que corresponde a relevância do site em toda a internet, de modo que quanto mais acessado e referenciado um site, maior seu PageRank.
Para @s leitor@s do MultiSign, eu informo que o nosso PageRank é 3, tendo em torno de 20 visitas por dia (segundo esta fonte).
Uma forma rápida, simples, fácil e prática de descobrir o PageRank de um site (ou blog) é acessar este endereço e colocar o endereço do referido site (ou blog) na caixa de texto, então depois é só clicar em "PageRank".
Seguem abaixo o PageRank de alguns sites:
Para finalizar, peço que @s leitor@s comentem os posts e referenciem o MultiSign em outros sites para aumentarmos nosso PageRank.
Lembrando que o PageRank foi desenvolvido pelo Google, não que isto influencie algo mas é só uma informação adicional.
Para @s leitor@s do MultiSign, eu informo que o nosso PageRank é 3, tendo em torno de 20 visitas por dia (segundo esta fonte).
Uma forma rápida, simples, fácil e prática de descobrir o PageRank de um site (ou blog) é acessar este endereço e colocar o endereço do referido site (ou blog) na caixa de texto, então depois é só clicar em "PageRank".
Seguem abaixo o PageRank de alguns sites:
- www.orkut.com - 8
- www.yahoo.com.br - 8
- multisign.blogspot.com - 3
- hypercast.info - 3
- www.vivaolinux.com.br - 4
- www.linux.org - 5
- www.redhat.com - 8
- www.microsoft.com - 9 (argh!!)
- www.mozilla.org - 9 (yeah!!!)
- www.google.com.br - 9
- www.google.com - 10
Para finalizar, peço que @s leitor@s comentem os posts e referenciem o MultiSign em outros sites para aumentarmos nosso PageRank.
Lembrando que o PageRank foi desenvolvido pelo Google, não que isto influencie algo mas é só uma informação adicional.
sexta-feira, 26 de setembro de 2008
Mathematical morphology
One of most important areas in digital image processing is mathematical morphology.
It consists in max and min filters on the input image, changing the structural element (filter's mask).
Some applications of mathematical morphology are:
 Image 1: original image.
Image 1: original image.
 Image 2: result of original image's dilatation (max filter).
Image 2: result of original image's dilatation (max filter).
The GIMP (GNU Image Manipulation Program) does these mathematical morphology operations, as showed.
Before all, I want explain the structural element. It's a sub-set from input image and its form may change depeding on the application.
For example, given a image F(x,y) and a structural element which is a squad with 3 columns and 3 rows. The cited sub-set is Struc{F(x,y)} = {F(x-1,y-1), F(x-1,y), F(x-1,y+1), F(x,y-1), F(x,y), F(x,y+1), F(x+1,y-1), F(x+1,y), F(x+1,y+1)}. The structural element defines the neighborhood for each point (x,y) on the image.
The most common forms are:
It consists in max and min filters on the input image, changing the structural element (filter's mask).
Some applications of mathematical morphology are:
- Filtering of binary images;
- Objects resize;
- Enhancement of specific areas.
 Image 1: original image.
Image 1: original image. Image 2: result of original image's dilatation (max filter).
Image 2: result of original image's dilatation (max filter).
Before all, I want explain the structural element. It's a sub-set from input image and its form may change depeding on the application.
For example, given a image F(x,y) and a structural element which is a squad with 3 columns and 3 rows. The cited sub-set is Struc{F(x,y)} = {F(x-1,y-1), F(x-1,y), F(x-1,y+1), F(x,y-1), F(x,y), F(x,y+1), F(x+1,y-1), F(x+1,y), F(x+1,y+1)}. The structural element defines the neighborhood for each point (x,y) on the image.
The most common forms are:
- Squad;
- Circle;
- Cross;
- Dash (diagonal, vertical or horizontal);
- Diamond.
quinta-feira, 25 de setembro de 2008
Momentos centrados
Este é o primeiro post que faço sobre minhas pesquisas acerca do meu mestrado.
Para refrescar a memória dos que já sabem do que se trata o meu mestrado e para informar os leitores que vieram depois que parei de escrever sobre estas pesquisas:
Meu projeto de mestrado consiste em desenvolver um sistema de reconhecimento automático da Libras (Língua de Sinais Brasileira).
Este projeto tem as seguintes etapas:
Agora faltava apenas a parte de extração de atributos, mas eu estava estudando o livro de reconhecimento de padrões adotado na disciplina (quem quiser saber qual é o livro, pode pedir em comentário(s)) e vi algo sobre momentos centrados, e vi também que estes momentos são atributos extraídos dos objetos presentes em imagens para classificá-los.
Por fim, achei que seria interessante falar sobre os momentos centrados.
Os momentos centrados são provenientes da mecância clássica, pois consistem em momentos baseados no centro de massa dos corpos (objetos).
A equação abaixo mostra como são calculados os momentos centrados:
 Em que f(x,y) é a imagem. Os termos p e q são ordens do momento, como fazemos em estatística nos momentos de 1ª (média), 2ª (variância), 3ª (curtosis), 4ª, etc.... ordem; podemos observar que estes momentos podem ser escritos até como termos de esperança matemática (olhe aqui).
Em que f(x,y) é a imagem. Os termos p e q são ordens do momento, como fazemos em estatística nos momentos de 1ª (média), 2ª (variância), 3ª (curtosis), 4ª, etc.... ordem; podemos observar que estes momentos podem ser escritos até como termos de esperança matemática (olhe aqui).
Os centros de massa dos objetos (corpos) são dados pela equação abaixo:
 Estes momentos centrados são descritores muito úteis, pois são invariantes a translação dos objetos, porém, observa-se que estes momentos são dependentes à rotação.
Estes momentos centrados são descritores muito úteis, pois são invariantes a translação dos objetos, porém, observa-se que estes momentos são dependentes à rotação.
Para tornar obter descritores indendentes tanto a translação e a rotação, um pesquisador chamado M. Hu propôs as seguintes combinações dos momentos, gerando novas grandezas:

Com isto fecho o que espero ser pelo menos o material para minha qualificação de mestrado.
Para refrescar a memória dos que já sabem do que se trata o meu mestrado e para informar os leitores que vieram depois que parei de escrever sobre estas pesquisas:
Meu projeto de mestrado consiste em desenvolver um sistema de reconhecimento automático da Libras (Língua de Sinais Brasileira).
Este projeto tem as seguintes etapas:
- Aquisição da(s) imagem(ns) por uma webcam;
- Segmentação do objeto de interesse (mão);
- Extração de atributos da imagem;
- Classificação da imagem de acordo com os atributos.
Agora faltava apenas a parte de extração de atributos, mas eu estava estudando o livro de reconhecimento de padrões adotado na disciplina (quem quiser saber qual é o livro, pode pedir em comentário(s)) e vi algo sobre momentos centrados, e vi também que estes momentos são atributos extraídos dos objetos presentes em imagens para classificá-los.
Por fim, achei que seria interessante falar sobre os momentos centrados.
Os momentos centrados são provenientes da mecância clássica, pois consistem em momentos baseados no centro de massa dos corpos (objetos).
A equação abaixo mostra como são calculados os momentos centrados:
 Em que f(x,y) é a imagem. Os termos p e q são ordens do momento, como fazemos em estatística nos momentos de 1ª (média), 2ª (variância), 3ª (curtosis), 4ª, etc.... ordem; podemos observar que estes momentos podem ser escritos até como termos de esperança matemática (olhe aqui).
Em que f(x,y) é a imagem. Os termos p e q são ordens do momento, como fazemos em estatística nos momentos de 1ª (média), 2ª (variância), 3ª (curtosis), 4ª, etc.... ordem; podemos observar que estes momentos podem ser escritos até como termos de esperança matemática (olhe aqui).Os centros de massa dos objetos (corpos) são dados pela equação abaixo:
 Estes momentos centrados são descritores muito úteis, pois são invariantes a translação dos objetos, porém, observa-se que estes momentos são dependentes à rotação.
Estes momentos centrados são descritores muito úteis, pois são invariantes a translação dos objetos, porém, observa-se que estes momentos são dependentes à rotação.Para tornar obter descritores indendentes tanto a translação e a rotação, um pesquisador chamado M. Hu propôs as seguintes combinações dos momentos, gerando novas grandezas:

Com isto fecho o que espero ser pelo menos o material para minha qualificação de mestrado.
terça-feira, 23 de setembro de 2008
apt-get
De tanto ver tutoriais (on-line) e dicas e eu mesmo tanto falo no apt-get que resolvi fazer um post sobre este software maravilhoso.
O apt-get, da forma que me refiro, consiste em um pacote de vários aplicativos:
Cada aplicativo por sua vez tem seus parâmetros específicos.
Parâmetros do apt-cache:
Então agora temos o comando apt-cache search *****************, em que a sequência de asteriscos (*****************) representa o que você está procurando, por exemplo vamos procurar algum programa relacionado a P2P:
 Observa-se que existem vários programas disponíveis envolvendo P2P.
Observa-se que existem vários programas disponíveis envolvendo P2P.
O apt-cache mostra tanto o nome do programa como uma pequena descrição do mesmo.
Agora para instalar o programa nós usamos o apt-get.
Os possíveis parâmetros do apt-get:
O remove vai desinstalar o software indicado.
O upgrade vai atualizar o software indicado.
O update vai atualizar a lista de softwares disponível.
O install vai instalar o software indicado.
O apt-get também suporta manipular vários softwares al mesmo tempo.
O comando update é feito da seguinte forma:
 Observando que o apt-get precisa da permissão de super-user (sudo, su, root) para ser executado (é só colocar "sudo apt-get update" no terminal).
Observando que o apt-get precisa da permissão de super-user (sudo, su, root) para ser executado (é só colocar "sudo apt-get update" no terminal).
Estes endereços que aparecem são os repositórios de software, no caso, do Ubuntu.
E para trabalhar com um aplicativo, seja para instalar, atualizar ou remover, é só digitar "sudo apt-get {parâmetro} {nome do software}" no terminal.
No caso, a gente (usuários do apt-get) costuma sudo apt-get update para atualizar a lista de softwares, depois usamos o apt-cache search {palavra relacionada ao software desejado} para identificar o que buscamos (a busca também é feita na descrição do software) em seguida usamos o sudo apt-get install {software desejado} para instalarmos o software nosso de cada dia.
O apt-get, da forma que me refiro, consiste em um pacote de vários aplicativos:
- apt-cache
- apt-extracttemplates
- apt-key
- apt-cdrom
- apt-ftparchive
- apt-mark
- apt-config
- apt-get
- apt-sortpkgs
Cada aplicativo por sua vez tem seus parâmetros específicos.
Parâmetros do apt-cache:
- add
- dump
- madison
- rdepends
- showpkg
- unmet
- depends
- dumpavail
- pkgnames
- search
- showsrc
- xvcg
- dotty
- gencaches
- policy
- show
- stats
Então agora temos o comando apt-cache search *****************, em que a sequência de asteriscos (*****************) representa o que você está procurando, por exemplo vamos procurar algum programa relacionado a P2P:
 Observa-se que existem vários programas disponíveis envolvendo P2P.
Observa-se que existem vários programas disponíveis envolvendo P2P.O apt-cache mostra tanto o nome do programa como uma pequena descrição do mesmo.
Agora para instalar o programa nós usamos o apt-get.
Os possíveis parâmetros do apt-get:
- autoclean
- check
- dselect-upgrade
- remove
- upgrade
- autoremove
- clean
- install
- source
- build-dep
- dist-upgrade
- purge
- update
O remove vai desinstalar o software indicado.
O upgrade vai atualizar o software indicado.
O update vai atualizar a lista de softwares disponível.
O install vai instalar o software indicado.
O apt-get também suporta manipular vários softwares al mesmo tempo.
O comando update é feito da seguinte forma:
 Observando que o apt-get precisa da permissão de super-user (sudo, su, root) para ser executado (é só colocar "sudo apt-get update" no terminal).
Observando que o apt-get precisa da permissão de super-user (sudo, su, root) para ser executado (é só colocar "sudo apt-get update" no terminal).Estes endereços que aparecem são os repositórios de software, no caso, do Ubuntu.
E para trabalhar com um aplicativo, seja para instalar, atualizar ou remover, é só digitar "sudo apt-get {parâmetro} {nome do software}" no terminal.
No caso, a gente (usuários do apt-get) costuma sudo apt-get update para atualizar a lista de softwares, depois usamos o apt-cache search {palavra relacionada ao software desejado} para identificar o que buscamos (a busca também é feita na descrição do software) em seguida usamos o sudo apt-get install {software desejado} para instalarmos o software nosso de cada dia.
segunda-feira, 22 de setembro de 2008
Auto-image
I saw this video today.
The elephant makes a fantastic picture by itself.
Comment about your opinion.
The elephant makes a fantastic picture by itself.
Comment about your opinion.
Auto-imagem
Hoje vi este vídeo e não poderia deixar de postá-lo:
Trata-se de um elefante que faz uma pintura fantástica.
O vídeo é longo mas vale a pena assistir até o final.
Trata-se de um elefante que faz uma pintura fantástica.
O vídeo é longo mas vale a pena assistir até o final.
sábado, 20 de setembro de 2008
De onde vem o resto da energia?
Assista o vídeo abaixo:
Agora pensemos:
O inventor diz que com 400Watts consegue gerar 1600Watts, de onde vem os outros 1200Watts?
Com as conversões de energia, sempre existem perdas então qualquer forma de converter a energia elétrica em outra natureza (energia mecânica ou térmica) e depois voltar para energia elétrica iria ter 2 vezes perdas.
Uma solução poderia ser usar buffers de corrente, aí poderia-se manter a tensão (220V ~ 60Hz, por exemplo) e aumentar a capacidade de corrente, pois a potência é o produto da tensão pela corrente, mas neste caso não fica claro o que poderia ser o buffer de corrente.
Em eletrônica (circuitos de baixa potência, como celulares e computadores) os buffers de correntes são apenas transistores operando em regiões de saturação.
Enfim, caso o inventor venha a ler este post, eu ficaria muito feliz se ele entrasse em contato para explicar como funciona o multiplicador de energia.
Agora pensemos:
O inventor diz que com 400Watts consegue gerar 1600Watts, de onde vem os outros 1200Watts?
Com as conversões de energia, sempre existem perdas então qualquer forma de converter a energia elétrica em outra natureza (energia mecânica ou térmica) e depois voltar para energia elétrica iria ter 2 vezes perdas.
Uma solução poderia ser usar buffers de corrente, aí poderia-se manter a tensão (220V ~ 60Hz, por exemplo) e aumentar a capacidade de corrente, pois a potência é o produto da tensão pela corrente, mas neste caso não fica claro o que poderia ser o buffer de corrente.
Em eletrônica (circuitos de baixa potência, como celulares e computadores) os buffers de correntes são apenas transistores operando em regiões de saturação.
Enfim, caso o inventor venha a ler este post, eu ficaria muito feliz se ele entrasse em contato para explicar como funciona o multiplicador de energia.
sexta-feira, 19 de setembro de 2008
OPP - Isto é engenharia social!
Hoje vi este site e tomei conhecimento do OPP (Open Prosthetics Project) que é um projeto de desenvolvimento tecnológico open-source.
O foco deste projeto é desenvolver prótestes artificiais (braços e pernas, por exemplo) em um modelo aberto e colaborativo, como já existe com o software livre.
A idéia é cada um colaborar com o que puder, seja doações financeiras ou conhecimentos e/ou recursos em engenharia, medicina, computação, marketing, etc....
Como o modelo de desenvolvimento é aberto, toda a informação desenvolvida está (e estará) disponível para qualquer pessoa no planeta a distância de um clique do mouse.
Como o modelo de desenvolvimento é colaborativo, as pessoas envolvidas poderão trocar experiências e enriquecer cada vez mais as próteses, tornando-as mais eficazes e eficientes (caso alguém queira saber a diferença entre eficácia e eficiência, é só fazer um comentário perguntando), além de baratear o custo para o usuário final.
O próprio fundador do OPP perdeu sua mão na Guerra do Iraque e foi isto que o motivou a criar o projeto.
Por fim, convido a todos os leitores do MultiSign que ao menos conheçam o trabalho que está sendo desenvolvido, é só clicar aqui.
O foco deste projeto é desenvolver prótestes artificiais (braços e pernas, por exemplo) em um modelo aberto e colaborativo, como já existe com o software livre.
A idéia é cada um colaborar com o que puder, seja doações financeiras ou conhecimentos e/ou recursos em engenharia, medicina, computação, marketing, etc....
Como o modelo de desenvolvimento é aberto, toda a informação desenvolvida está (e estará) disponível para qualquer pessoa no planeta a distância de um clique do mouse.
Como o modelo de desenvolvimento é colaborativo, as pessoas envolvidas poderão trocar experiências e enriquecer cada vez mais as próteses, tornando-as mais eficazes e eficientes (caso alguém queira saber a diferença entre eficácia e eficiência, é só fazer um comentário perguntando), além de baratear o custo para o usuário final.
O próprio fundador do OPP perdeu sua mão na Guerra do Iraque e foi isto que o motivou a criar o projeto.
Por fim, convido a todos os leitores do MultiSign que ao menos conheçam o trabalho que está sendo desenvolvido, é só clicar aqui.
Situação destes dias
Aos leitores do MultiSign que acompanharam o blog estes dias, devem ter percebido que deste quarta-feira eu não postei nada, pois bem, eu estava com uns problemas de saúde (comecei a sentir-me mal na terça (16/09) a tarde) mas agora está tudo bem, deve ter sido algo que comi, fui conversar com um médico e ele confirmou que deve ter sido isto mesmo.
Fiquei feliz em ver que mesmo sem as postagens a frequência de visitas não teve grandes alterações, ontem mesmo teve mais de 20 visitas (foram 21).
Mudando de assunto: sobre os posts que tratei de GPIB, eu os fiz como parte de um estudo que estou fazendo para um professor aqui na UFC.
Enfim, é só isto mesmo. Em breve espero poder voltar a ativa como antes e fazer posts interessantes. Para isto, peço também a colaboração dos leitores com comentários e votos nas enquetes.
Fiquei feliz em ver que mesmo sem as postagens a frequência de visitas não teve grandes alterações, ontem mesmo teve mais de 20 visitas (foram 21).
Mudando de assunto: sobre os posts que tratei de GPIB, eu os fiz como parte de um estudo que estou fazendo para um professor aqui na UFC.
Enfim, é só isto mesmo. Em breve espero poder voltar a ativa como antes e fazer posts interessantes. Para isto, peço também a colaboração dos leitores com comentários e votos nas enquetes.
terça-feira, 16 de setembro de 2008
GPIB - General Purpose Interface Bus
GPIB (General Purpose Interface Bus) is a communication interface between diferents devices, as USB, serial port, parallel port, etc....
The National Instrument$ and Angilent ($$$) support this interface (developing drivers and aplications), this is the first and problably the last post that I do about anything that use proprietary software, I want only show that is possible use free software in this type of situation.
So, the GPIB was developed by cientists, for your devices, and they earn rates about 5MB/s (yes, 5 Mega Bytes). Few time later the IEEE maked the standard IEEE-488.
This standard is very commom is devices of materials analysis, radio-frequency, etc.... those are used in "down engeneering".
But the Scilab has a toolbox for GPIB systems (here) and it works on GNU/Linux (if the toolbox doesn't work on GNU/Linux I don't make this post)!
About the GPIB:
I'm having sucess with Scilab and GPIB.
Finishing: we don't need use MetLab or LambVIEW or any proprietary software (they smell badly!).
The National Instrument$ and Angilent ($$$) support this interface (developing drivers and aplications), this is the first and problably the last post that I do about anything that use proprietary software, I want only show that is possible use free software in this type of situation.
So, the GPIB was developed by cientists, for your devices, and they earn rates about 5MB/s (yes, 5 Mega Bytes). Few time later the IEEE maked the standard IEEE-488.
This standard is very commom is devices of materials analysis, radio-frequency, etc.... those are used in "down engeneering".
But the Scilab has a toolbox for GPIB systems (here) and it works on GNU/Linux (if the toolbox doesn't work on GNU/Linux I don't make this post)!
About the GPIB:
- Supports until 32 devices simultaneously;
- In a GPIB network exists 3 types of elements: talkers, listeners and controllers;
- Each device can be acessed and controlled individually.
I'm having sucess with Scilab and GPIB.
Finishing: we don't need use MetLab or LambVIEW or any proprietary software (they smell badly!).
domingo, 14 de setembro de 2008
Thanks
I'm doing this post because I want really thanks the MultiSign's readers.
By this source, the MultiSign reached 791 visits until yesterday (Aug 13, finishing one month since the starting of count), then the average of visits is 25.516129032258064 per day (remember that August has 31 days).
I would ask that the readers comment the posts, because I do each post for you.
By this source, the MultiSign reached 791 visits until yesterday (Aug 13, finishing one month since the starting of count), then the average of visits is 25.516129032258064 per day (remember that August has 31 days).
I would ask that the readers comment the posts, because I do each post for you.
Agradecimento
Venho por meio deste post fazer um sincero agradecimento aos leitores do blog.
Segundo esta fonte, o MultiSign alcançou 791 visitas até ontem (fechando 1 mês desde o começo da contagem), obtendo assim uma média de 25,516129032258064 visitas por dia (lembrando que agosto tem 31 dias).
Sinto que neste período houveram pouquíssimos comentários, então peço (novamente) que os leitores comentem os posts para enriquecermos o MultiSign.
Segundo esta fonte, o MultiSign alcançou 791 visitas até ontem (fechando 1 mês desde o começo da contagem), obtendo assim uma média de 25,516129032258064 visitas por dia (lembrando que agosto tem 31 dias).
Sinto que neste período houveram pouquíssimos comentários, então peço (novamente) que os leitores comentem os posts para enriquecermos o MultiSign.
quinta-feira, 11 de setembro de 2008
GPIB - Interface de Uso Geral
GPIB (General Purpose Interface Bus) é uma interface de comunicação entre dispositivos, como a USB, paralela, serial, PS2, etc....
Esta interface é suportada (tem como suporte) pela National Instrument$ e a Agilent ($$$), este é o primeiro e se possível último post que faço de algo que usa software proprietário aqui no MultiSign, minha intenção é apenas mostrar que é possível resolver os problemas, por mais complexos que sejam, com o software livre.
Pois bem, a GPIB foi desenvolvida por um pesquisador e como ele conseguia taxas de transmissão muito altas (da ordem de 5MB/s - é byte mesmo) em pouco tempo o IEEE adotou como um dos padrões de comunicação entre dispositivos.
Atualmente esta interface é muito usada para dispositivos de análise de materiais, rádio-frequência, etc... que são usados por "engenharia de base".
Algo que me deixou muito motivado a fazer este post foi a existência de uma toolbox de comunicação GPIB para o Scilab (aqui) e esta mostrou-se muito funcional, e ainda existe uma versão para GNU/Linux (se não existisse eu não estaria fazendo este post).
Falando um pouco do padrão GPIB:
- este é capaz de suportar até 32 dispositivos ao mesmo tempo;
- existem 3 tipos de elementos em uma rede GPIB: controladores (controllers), ouvintes (listeners) e emissores (talkers);
- cada dispositivo pode ser acessado e controlado independentemente.
É isso mesmo, agora aos usuários da interface GPIB: existem soluções livres para usar a interface, existem até bibliotecas de C/C++ e Python para GNU/Linux destinadas a fazer o uso e controle de dispositivos GPIB.
Resumindo: não precisamos mais de LambVIEW nem MetLab nem qualquer um destes softwares proprietários que não valem nada!
Assinar:
Comentários (Atom)